Introduction
Ever since Martin Fowler and James Lewis wrote their original article on microservices in 2014, it has become the defacto standard for any sort of large-scale enterprise architecture. The microservices architectural style has allowed enterprises to transform their IT organizational structure along business unit lines, where each unit delivers separately deployable services whose only interaction points are the APIs (usually REST) they expose. Coupled with the rise of Docker containers and especially platforms like Kubernetes, microservices has also considerably eased the burden for enterprise Ops teams. This has meant that the modern enterprise that adopts microservices is capable of churning out features at a tremendous pace and with high quality.
Having said that, the microservices architecture comes with its own set of challenges, as Martin Fowler himself wrote about on his website. Like almost everything else in software engineering, the microservices architecture requires architects to carefully consider many factors including, and especially, the existing IT landscape of the organisation. While choosing microservices as the default for a Greenfield project might largely make sense (conditions applied), introducing it into a legacy ecosystem that isn’t ready for it is a non-trivial challenge.
In this article, we will take a look at one such problem statement where a microservices approach appears to be a good fit due to the many benefits it offers. However, when we try to introduce this pattern, we run into some hurdles, forcing us to consider alternatives. We will also learn about one such alternative, which will prove to be quite effective in this particular use-case. (Note that this blog post is heavily inspired by a recent legacy transformation journey I have been on for a client in the financial services domain.)
The Enterprise-Wide Legacy Database Problem
For our journey, let us consider a problem statement that will be familiar to folks who have worked on any sort of large-scale enterprise transformation.
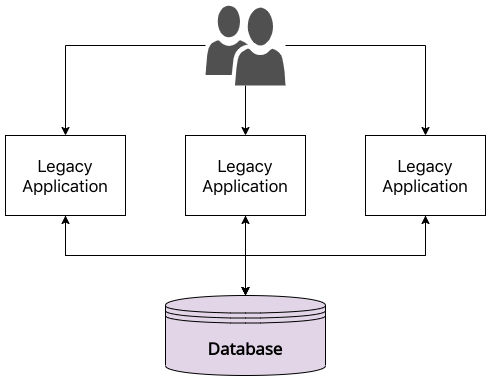
What we see in the above picture is the following:
- A large, monolithic legacy database that serves as the source of truth for the entire enterprise. In an ideal world, this is what we will need to break down as we implement our microservices architecture. In my experience, these databases usually tend to have pretty well-defined schemas. This will come in handy as we proceed further into this problem statement.
- Multiple legacy systems that both read from and write to the above database.
Having multiple legacy applications not only poses a technical challenge for a legacy rewrite, it is also normally one of the main drivers for enterprises to rebuild, since users find navigating across multiple legacy applications quite painful.
One thing we do not see in the above diagram but that will be apparent to folks who have faced a problem statement like this is that a ecosystem like the above is what primarily leads to slow delivery of features in enterprises. This is normally due to a lack of confidence in the overall ecosystem with a small change necessitating a full-blown inter-application regression before it can reach production. This then again is one of the main drivers why enterprises want to move away from the monolithic database that powers multiple disparate applications.
Introducing Microservices via Strangulation
One obvious solution when presented with a legacy rewrite like this is to adopt the pattern that Martin Fowler and Sam Newman refer to as the Strangler Fig Application. Unsurprisingly this pattern goes well with a microservices-based architecture.
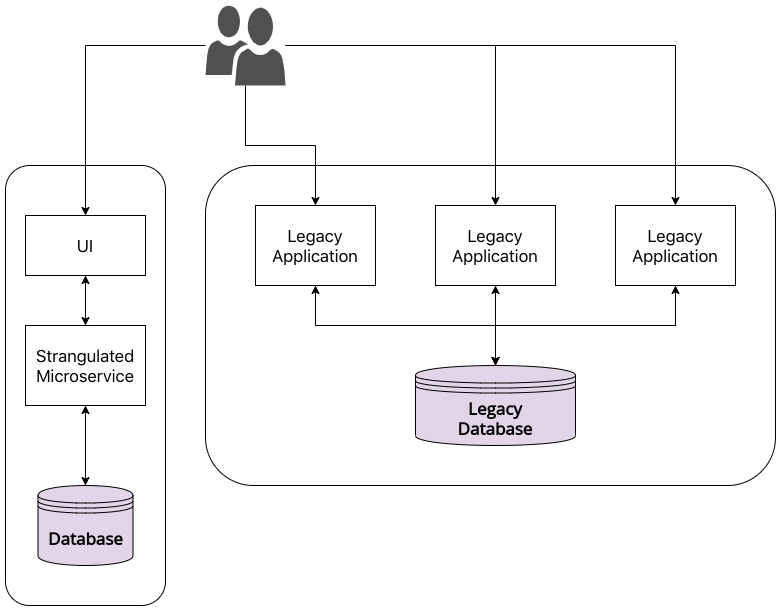
In this pattern, we simply find and start with the highest-value, lowest-cost domain from the business standpoint, build a microservice(s) for it, porting over functionality periodically till we run out. Once we have done this for all the domains within the business, what we are left with (hopefully) is an enterprise that is built on top of a multitude of microservices, each with its own database and deployment pipeline, thus reaching the enterprise promised land.
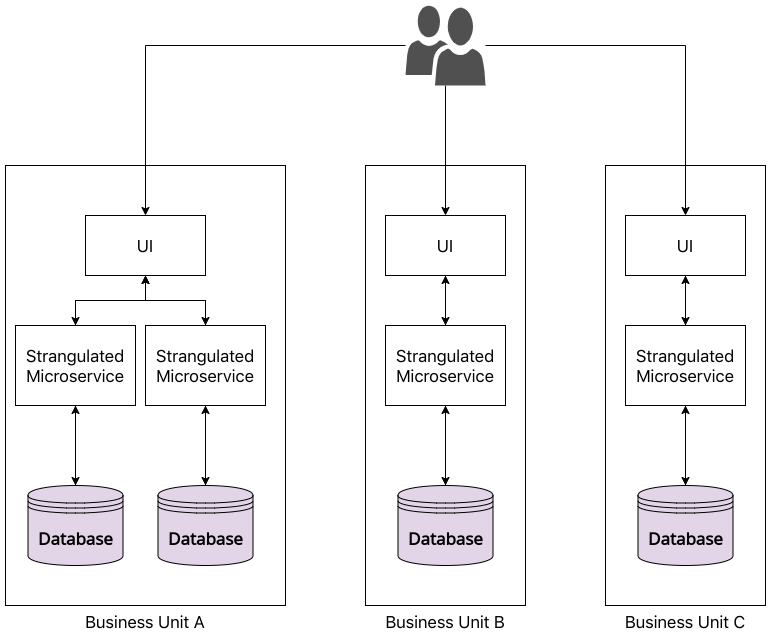
While that sounds enticing, there are some pitfalls and hurdles one normally faces thanks to the peculiarities of the enterprise legacy landscape.
The Painful Reality of Legacy Integration
Remember that large, monolithic database we spoke about when we introduced our problem statement, well that is what usually stops our legacy rewrite from reaching the microservices-filled promised land. To illustrate why this is the case, let me expand our original legacy diagram to more closely align with reality.
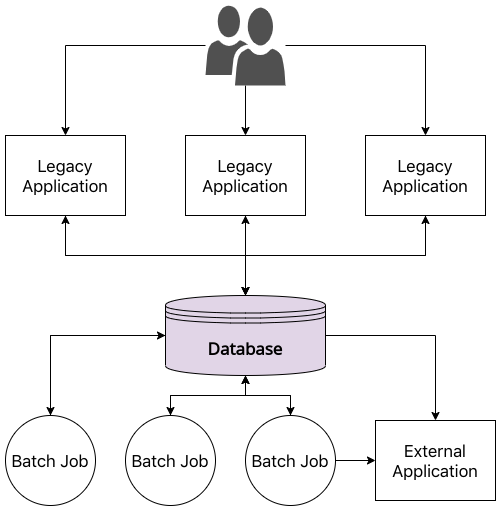
As we see now, it is not just the multiple legacy applications that read from and write to our monolithic database, there’s also:
- Batch Jobs - These are a mainstay of most enterprises. They can be anything from nightly computation jobs that write back to the database to jobs that publish data to OLAP databases to ones that publish to external systems.
- External Systems - While these are less common, we cannot rule them out, especially in the financial services domain where enterprises will find themselves needing to publish data to third-party regulators periodically.
What does this mean for us as we try to strangulate a domain from the monolithic database into one of our microservices?
In short, building a microservice on top of a legacy monolithic database with dependencies means that any new data that we generate needs to be synced back to the legacy database. And vice versa.
As one might imagine, this is a non-trivial problem at the best of times. A quick search of the Internet tells us as much. (A random search yielded me this SO question, of which the top answer provides many solutions too.)
It is not that there aren’t solutions to this particular problem. On the contrary, there are many. It is simply that most of them can be time and money consuming to implement. If the enterprise has plenty of time and an unlimited budget at their disposal to go ahead and do this, it would be the ideal choice. (And I have seen it done successfully on past projects with similar landscapes.)
But what happens when time and money are in limited supply and we still need to deliver functioning software built on modern technologies solving the particular business problem at hand?
Leaving the Legacy Database Untouched
At this point, one might ask a pertinent question: What happens if we choose not to rewrite the legacy database and simply build our new, fancy application on top of it, while still following all the modern best practices for microservice development and deployment. For one, we cannot call it a “microservices-architecture” anymore, since the key underpinning of that pattern is that every service has its own database.
By leaving a large monolithic database untouched and simply building services on top it, we end up with what has been referred to as Services-Based Architecture by Neal Ford and Mark Richards.
To borrow the diagram from The Fundamentals of Software Architecture, we end up with an architecture that somewhat looks like this:
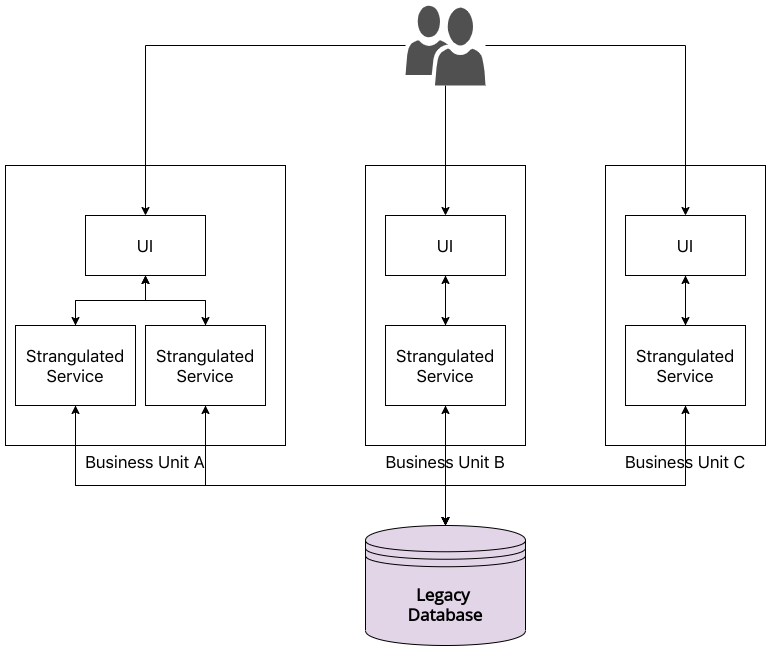
Now there are many variations of this architectural style that I won’t go deep into. I suggest reading the above book to get a good understanding of all of them.
Benefits of Services Based Architecture
With this style, we get many of the same benefits that a microservices style of architecture would give us:
- Infrastructure Point of View
- Ease of Deployment
- Reliability and Scalability
- Performance
- Development Experience Point of View
- Modularity and Decoupling
- Easy Testability
While those are fairly obvious benefits of splitting our monolith into individual services, if we take the time to revisit our earlier problem statement, we will find that a few other benefits specific to services-based architecture reveal themselves.
Time and Money Savings
One of the considerations I put forth as to why a pure microservices approach was not possible was that we didn’t have the time and budget necessary to implement a two-way data sync mechanism between the legacy and the new database.
Adopting a services-based architecture gets rid of that particular problem. Remember what I mentioned earlier about the legacy database being well-designed, this is what gives us the confidence to adopt this architectural style in this particular instance.
By reusing the legacy database, we will have savings in terms of both time and overall budget, resulting in a faster time to market for our legacy rewrite.
Simplicity
Going back to our data-syncing challenge, it is worth mentioning that building a syncing mechanism is not only time and budget consuming, but also adds a layer of complexity to our architecture. This mechanism is code we will have to write and maintain. Not only that, no such mechanism is fool-proof, and if we happen to end up with missing records, debugging can be a pain.
Once again, services based architecture eradicates this completely. We end up with an architecture that is simpler and easier to maintain in the long-run.
Learnings from an Implementation
I have adopted this pattern on a recent project to much success. We have been able to meet all our delivery timelines and provide great value to the client, which I’m fairly confident wouldn’t have materialised had we proceeded with our original plan of implementing a microservices based architecture.
There are also a number of learnings I have from implementing a services-based architecture that I want to share.
Domain Driven Design still reigns supreme
To quote Neal Ford and Mark Richards:
Service-based architecture is a domain-partitioned architecture, meaning that the structure is driven by the domain rather than a technical consideration (such as presentation logic or persistence logic).
In our own approach to services-based architecture, we broke away from this key idea and split some of our services along technical lines. While I don’t want to go into the gory details, it basically came down to there being different mechanisms of integrating with the legacy systems and us building services as anti-corruption layers aligned with those mechanisms.
This caused challenges after a while since we had trouble in choosing which ACL service a particular functionality belonged to. If I were to do it again, I would choose domain-driven services over the above, despite some amount of additional effort that might be involved in extracting those different integration mechanisms as self-contained libraries.
Do not be eager to split services
In one of the key decisions that went astray, we eagerly chose to split a service into two. While we had our reasons at the time, it was only after we began developing that we realised the folly of this decision. Implementation of our first story within the new service ended up being such a massive copy-and-paste effort from another service that we eventually decided to go back on this decision.
Going back to Neal Ford and Mark Richards’ book, they mention that services in this architectural style typically tend to be coarse-grained rather than fine-grained. This is a key lesson to keep in mind when adopting this style.
Do not be afraid to mix and match with microservices
When working with (and rewriting) a pre-existing legacy database, there are high chances that we will discover new domain concepts not already prevalent in the business ecosystem. In such cases, we should not shy away from developing a traditional microservice for it.
That is one of the primary advantages of this architectural style: its ability to co-exist with other traditional microservices, functioning similar to one by exposing and consuming Restful APIs.
When to Use
One thing to bear in mind is that the services-based architectural style must usually be seen as an intermediate step in the legacy rewrite journey and not the destination. With this style, tight coupling at the database level persists obviously, and this makes evolving our architecture to the ever-changing user needs considerably more challenging than with a microservices approach.
That being said, I still consider it a pragmatic choice for many scenarios where microservices might be deemed too expensive; the problem statement I presented here being just one example of such a situation. In these scenarios, services-based architecture is a viable alternative. As we have seen, it offers most of the benefits of the former that makes it worth considering.
Further Reading
To understand more deeply about different architecture styles and services-based architecture in particular, I highly recommend Mark Richards’ and Neal Ford’s new book, Fundamentals of Software Architecture.
Conclusion
The services-based architecture style presents a viable alternative to other distributed architectural styles such as microservices or event-driven. Their simplicity and effectiveness make up for shortcomings such as tighter database coupling, making it a worthy addition to the architect’s toolbox.
This is especially true of legacy rewrites in complex enterprise ecosystems with a preexisting monolithic database. In such situations, adopting a services-based architecture as a first step alleviates many issues and allows development teams to deliver features faster, while still adhering to modern best practices such as automated unit/integration/contract testing and independent deployments.
Share This Article